
Serverless patterns for managing AWS Lambda at scale (from my re:Invent 2025 talk)

As serverless applications scale, managing hundreds of AWS Lambda functions becomes increasingly complex. After presenting this topic twice at AWS re:Invent 2025 to excellent reception, I wanted to share these insights more broadly. This article presents three proven architectural patterns that help teams organize Lambda functions at scale while reducing operational overhead.
Introduction
Building a serverless platform often starts with just a few AWS Lambda functions. Over time, however, as new features are added and the platform evolves, that number can quickly grow into the hundreds. At that scale, managing, deploying, and maintaining Lambda functions becomes increasingly complex.
This is a common challenge organizations face as they scale serverless architectures. As the number of Lambda functions increases, so does the operational overhead. One of the most frequent questions we hear from customers is:
“How should we properly structure and organize a large number of Lambda functions?”
In this article, we present three practical architectural patterns that help teams organize Lambda functions at scale, enabling them to grow serverless applications while keeping complexity under control.
The Starting Point: Single-Purpose Lambda Functions
When organizations first adopt AWS Lambda, they typically follow a straightforward approach: one function per responsibility. We refer to these as single-purpose Lambda functions.
Consider a typical e-commerce architecture:
GetProduct – Retrieve product details
AddCart – Add items to a shopping cart
RemoveCart – Remove items from the cart
GetCart – View the cart
SubmitOrder – Submit an order
ReserveInventory – Reserve inventory
ProcessPayment – Process payment
FulfilOrder – Complete the order
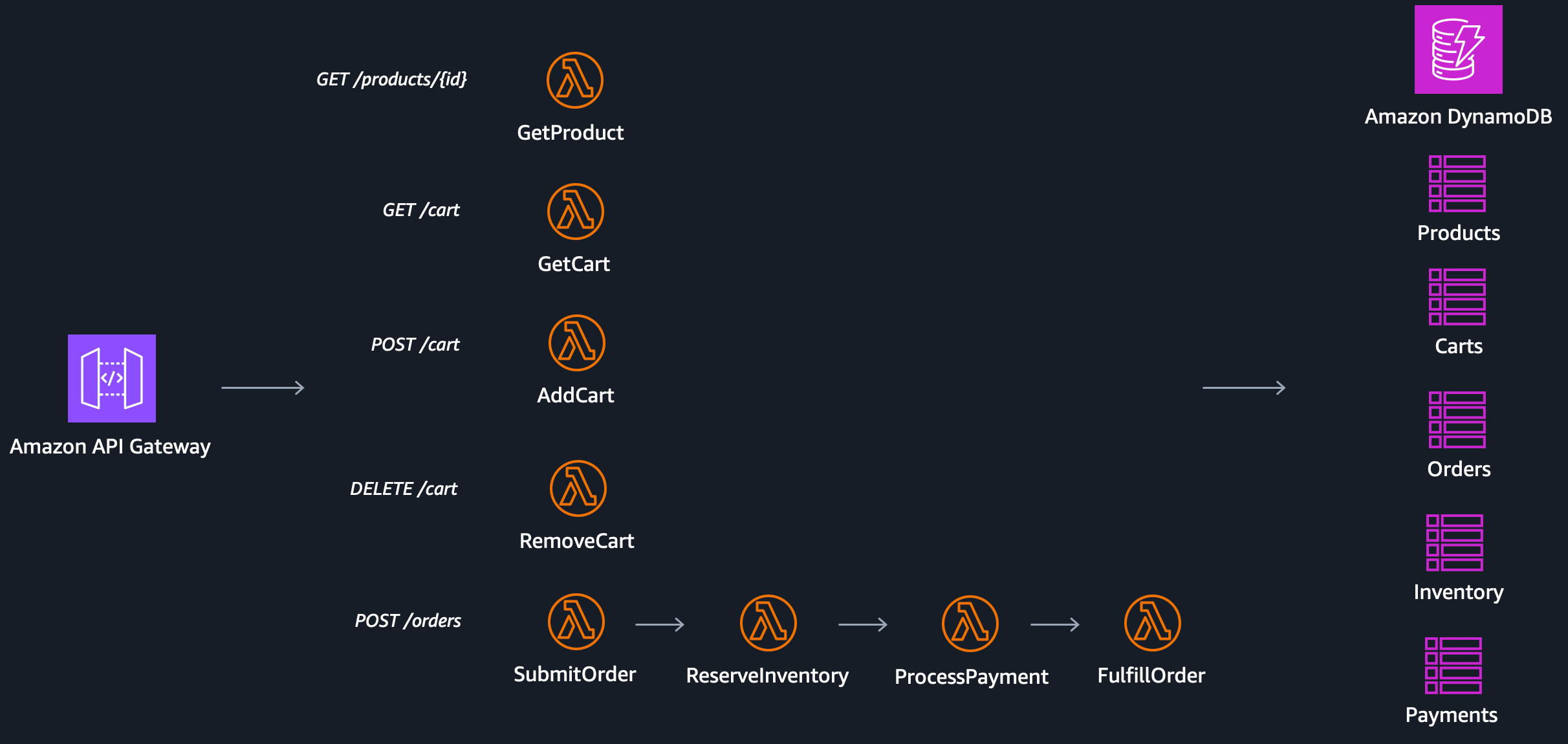
Amazon API Gateway acts as the front door, exposing HTTP endpoints and routing requests to the appropriate Lambda functions. Each function persists its data in a dedicated DynamoDB table.
This approach is perfectly valid and widely used. However, as organizations add features and scale their platforms, they often end up with hundreds or even thousands of Lambda functions in a single repository.
At scale, this typically results in:
A large, monolithic repository
A single, complex CI/CD pipeline
High deployment risk, where a failure impacts the entire system
To address these challenges, let’s explore three organizational patterns.
Pattern 1: Microservices
When all Lambda functions reside in a single repository backed by one AWS SAM template, complexity escalates quickly. Deployments become slow and risky, and ownership becomes unclear.
The solution is to apply microservices principles and bounded contexts to your serverless architecture.
Consider the cart-related functions: AddCart, RemoveCart, and GetCart. These functions:
Operate on the same domain (shopping cart)
Share the same data model and DynamoDB table
Are typically owned by the same team
These functions clearly belong together. Instead of managing them independently, group them into a dedicated service, such as a cart-service.
Repeat this process for other domains, including product, order, inventory, and payment. Each domain becomes its own service with:
A dedicated repository
Its own AWS SAM template
An independent CI/CD pipeline
In a true microservices architecture, services expose functionality through APIs rather than sharing infrastructure resources directly. As a result, SAM templates are typically self-contained and do not reference resources across services.
Benefits
This approach enables:
Independent development and deployment – Teams can ship changes without impacting unrelated services
Clear ownership – Each service has a well-defined boundary and responsible team
Reduced coupling – Services only include the dependencies they require
This is the foundation for scaling serverless systems both technically and organizationally.
Pattern 2: Lambda Web Adapter
Even with improved organization, teams may still manage a large number of Lambda functions. In many cases, these functions can be consolidated.
This is where the Lambda Web Adapter pattern becomes valuable. Instead of creating one Lambda function per HTTP endpoint, you run a traditional web framework inside a single Lambda function and handle routing internally.
For example, AddCart and RemoveCart both update the same DynamoDB table and operate within the same domain. These can be combined into a single manage_cart function.
Inside that function, you can use familiar frameworks such Express.js, Next.js, Flask, Django, Spring Boot, ASP.NET, Laravel, and so on. The Lambda Web Adapter makes this possible.
Benefits
This pattern offers several advantages:
Fewer cold starts – A single function replaces multiple endpoints
Shared initialization – SDK clients and database connections are initialized once
Familiar development model – Teams can use established web frameworks
Simpler testing – Routing and logic can be tested locally without mocking Lambda events
A Word of Caution
Consolidation should be applied carefully. Overuse can result in a monolithic Lambda function that negates the benefits of serverless design.
Keep functions aligned to a bounded context, and continuously monitor:
Function size
Memory usage
Execution time
Remember that a failure in a consolidated function can impact multiple operations.
When to Consolidate Functions
Consolidation is appropriate when functions:
Share common dependencies or downstream services
Have similar memory and performance requirements
Share IAM permissions
Have comparable initialization costs
If these factors align, consolidation is often beneficial.
Pattern 3: API Gateway Direct Integration
A common anti-pattern in serverless architectures is the use of Lambda functions that simply proxy requests to downstream services without applying any business logic.
For example, the GetCart function that retrieves an item from DynamoDB and returns it without transformation adds little value.
In such cases, the Lambda function can be removed entirely and replaced with an API Gateway direct integration.
With direct integrations, API Gateway communicates directly with AWS services such as DynamoDB or Step Functions, and others, eliminating the need for an intermediate Lambda function.
Benefits
This pattern provides:
Lower cost – No Lambda invocation charges
Lower latency – One less hop in the request path
No cold starts – API Gateway is always available
Reduced operational overhead – Fewer functions to manage
When to Use This Pattern
Use direct integrations when:
Performing simple CRUD operations
No business logic or complex validation is required
The goal is to minimize Lambda usage
Avoid this pattern when:
Complex transformations are needed
Business logic or orchestration is involved
Advanced error handling is required
Recap
To organize Lambda functions effectively at scale, consider the following patterns:
Microservices Organization – Group related functions by domain into independent services and repositories
Lambda Web Adapter – Consolidate related functions inside a single Lambda function
API Gateway Direct Integration – Eliminate unnecessary Lambda functions for simple operations
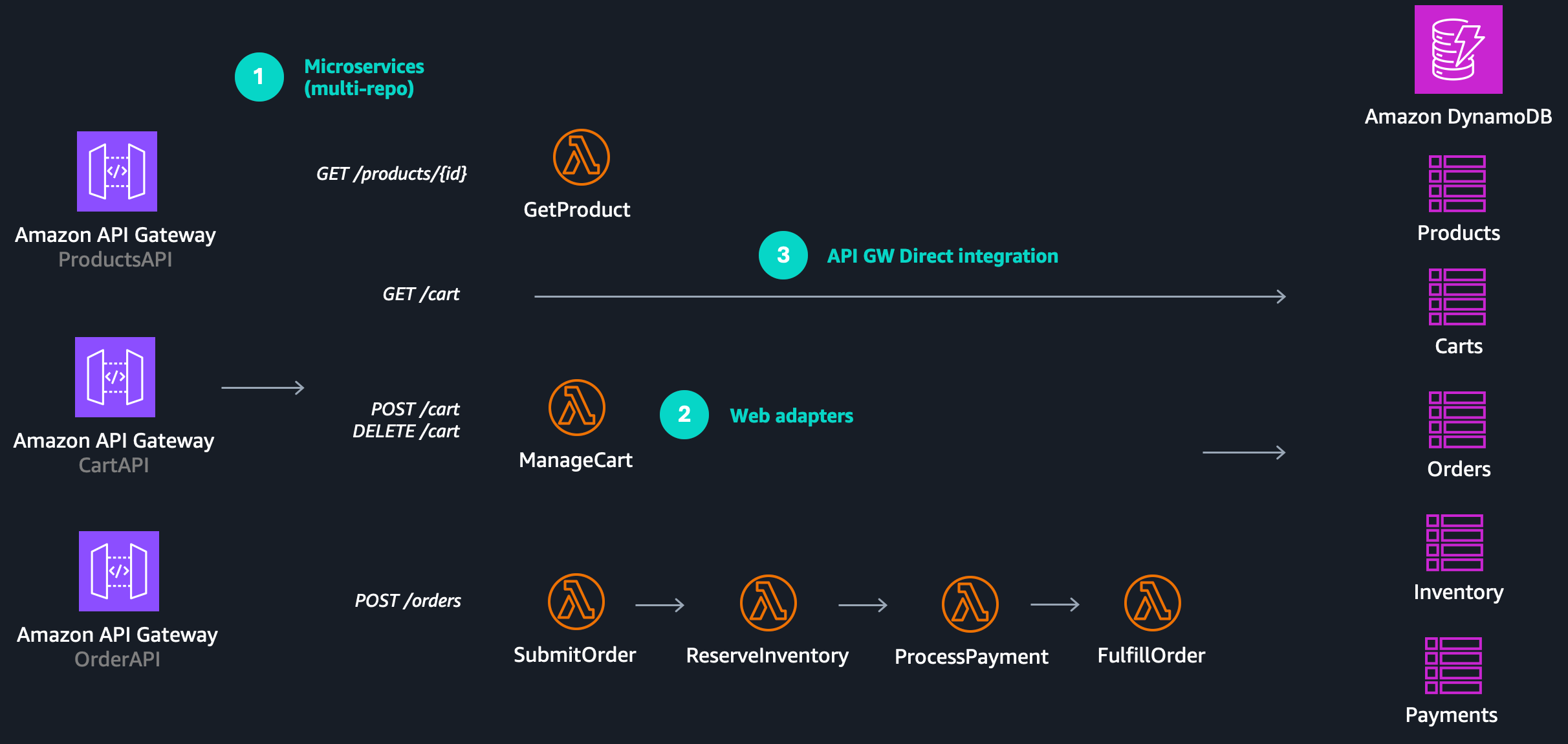
Applying these patterns allows teams to move from:
A single repository with scattered Lambda functions
To a domain-driven, multi-repository architecture
To fewer, more meaningful Lambda functions
And, where appropriate, to no Lambda functions at all
Conclusion
Organizing Lambda functions at scale does not need to be overwhelming. By grouping functions by domain, consolidating where appropriate, and leveraging API Gateway direct integrations, you can transform an unmanageable serverless environment into a clean, scalable, and maintainable architecture.
Start by reviewing your existing Lambda landscape. Identify shared domains, look for consolidation opportunities, and evaluate where direct integrations can reduce unnecessary compute. These incremental changes can significantly improve both developer productivity and operational efficiency.