
Serverless Data Processing Pipeline on AWS

In today's data-driven world, organizations need efficient, scalable, and cost-effective solutions for processing data. AWS's serverless offerings provide an excellent foundation for building robust data processing pipelines without managing infrastructure. This article explores how to architect a serverless data processing pipeline using Amazon S3, Lambda, Step Functions, EventBridge, and DynamoDB.
Why Serverless for Data Processing?
Before diving into the architecture, let's consider why serverless is compelling for data processing workflows:
Cost efficiency: You pay only for what you use, with no idle resources.
Automatic scaling: The pipeline handles varying workloads without manual intervention.
Reduced operational overhead: No servers to provision, patch, or maintain.
Built-in reliability: AWS services offer high availability and fault tolerance.
Simplified development: Focus on business logic rather than infrastructure.
The Pipeline Architecture
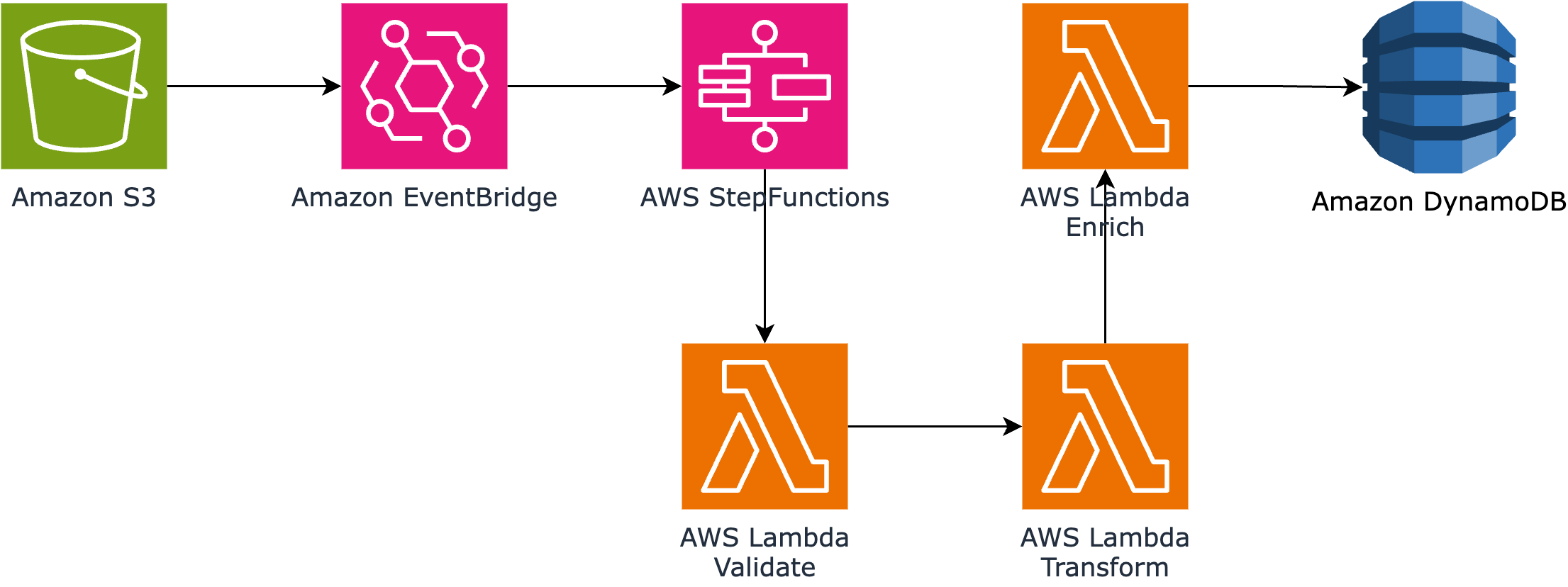
Our serverless data pipeline follows these high-level steps:
Data lands in an S3 bucket
S3 event notifications trigger an EventBridge rule
EventBridge initiates a Step Functions workflow
Step Functions orchestrates Lambda functions that:
Validate the data
Transform the data
Enrich the data with additional context
Load the processed data into DynamoDB
Let's explore each component in detail.
Amazon S3: The Data Source
S3 serves as our pipeline's entry point. Whether you're receiving batch uploads from partners, collecting IoT device data, or aggregating logs, S3 provides a durable, highly available storage solution.
Key considerations:
Configure appropriate bucket policies and access controls
Consider organizing data using prefixes for different data types or sources
Set up lifecycle policies to archive older data automatically
Enable versioning for data integrity and recovery
EventBridge: The Event Router
When new files arrive in S3, they generate events. Amazon EventBridge captures these events and routes them to the appropriate target based on rules you define.
Benefits of using EventBridge:
Decouples the event source (S3) from event consumers
Enables filtering events based on metadata (file type, prefix, size)
Facilitates sending events to multiple destinations if needed
Provides built-in retry capabilities
Allows for scheduled event processing
Step Functions: The Orchestrator
AWS Step Functions serves as the conductor of our data processing orchestra, managing the workflow across multiple Lambda functions. Rather than chaining Lambdas directly (which creates tight coupling and makes error handling difficult), Step Functions provides:
Workflow advantages:
Visual workflow representation
Built-in error handling and retry mechanisms
State management for long-running processes
Parallel processing capabilities
Execution history for troubleshooting
Integration with over 200 AWS services
For our data pipeline, a typical workflow might include:
Initial validation state: Ensure the data meets format requirements
Transformation state: Convert, normalize, or restructure the data
Enrichment state: Add additional context from other sources
Choice state: Determine routing based on data characteristics
Loading state: Write the processed data to DynamoDB
Lambda: The Processing Engine
Lambda functions perform the actual data processing work. Each function should follow the single responsibility principle, focusing on one aspect of the pipeline.
Key Lambda functions in our pipeline:
Validator Lambda:
Checks file formats and schema compliance
Rejects malformed data early in the pipeline
Reports validation errors for troubleshooting
Transformer Lambda:
Converts data formats (CSV to JSON, XML to JSON)
Normalizes inconsistent data
Filters unnecessary fields
Handles data type conversions
Enrichment Lambda:
Adds metadata or contextual information
Joins data with reference information
Calls external APIs to augment data
Generates calculated fields
Loader Lambda:
Efficiently writes data to DynamoDB
Handles batching for performance
Implements idempotent operations
Manages error handling and retries
DynamoDB: The Data Destination
As the final stop in our pipeline, DynamoDB provides a fully managed NoSQL database service with:
Single-digit millisecond performance at any scale
Automatic scaling to handle varying workloads
Point-in-time recovery capabilities
Global tables for multi-region availability
Fine-grained access control
Design considerations for DynamoDB:
Plan your primary key structure carefully based on access patterns
Consider using TTL (Time To Live) for data that expires
Set up autoscaling or on-demand capacity to handle spikes
Enable DynamoDB Streams for further processing if needed
Monitoring and Troubleshooting
A robust pipeline needs comprehensive monitoring. AWS provides several tools:
CloudWatch Logs: Collects logs from all components
CloudWatch Metrics: Provides performance data and enables alerting
X-Ray: Traces requests through the pipeline for debugging
Step Functions execution history: Visualizes workflow execution
CloudWatch Dashboards: Creates custom views of pipeline health
Cost Optimization Strategies
To keep your serverless pipeline cost-effective:
Right-size Lambda functions: Allocate appropriate memory based on workload
Configure Lambda timeout wisely: Avoid unnecessarily long timeouts
Batch process small files: Combine small files before processing when possible
Use S3 storage classes: Move older data to Infrequent Access or Glacier
Consider DynamoDB capacity modes: Choose on-demand or provisioned based on patterns
Monitor and adjust: Regularly review usage and adjust resources
Security Best Practices
Security is paramount for any data pipeline:
Use IAM roles with least privilege access
Encrypt data at rest and in transit
Implement VPC endpoints for enhanced network security
Set up monitoring for unusual access patterns
Consider using AWS KMS for managing encryption keys
Regularly review and rotate credentials
Conclusion
A serverless data processing pipeline built on AWS S3, EventBridge, Step Functions, Lambda, and DynamoDB provides a scalable, cost-effective solution for handling data workflows of any size. By leveraging these managed services, you can focus on extracting value from your data rather than managing infrastructure.
This architecture pattern can be extended or modified to suit various use cases, from simple data transformation jobs to complex ETL workflows. The serverless nature ensures you're only paying for actual usage while gaining the benefits of automatic scaling and reduced operational overhead.
As you implement your own serverless data pipelines, remember that proper design upfront—considering data volumes, processing requirements, and access patterns—will help ensure success and avoid costly rearchitecting later.